یادداشتها
علیرضا تجری
ایجاد:
جمعه، 14 آبان 1400
ویرایش
چهارشنبه، 10 آذر 1400
مواجهه با overfit در شبکههای عصبی
شبکه عصبیای overfit است که نمودار validation loss آن صعودی شده باشد. به این معنا که شبکه عصبی، داده های یادگیری را به خوبی شناخته است اما بر روی داده های ارزیابی نتیجه خوبی ندارد. در این مقاله به علتهای این پدیده و نحوه مواجهه به آنها میپردازیم.
1. overfit چیست
در آموزش شبکههای عصبی ما به دنبال دو چیز هستیم: ۱) بهینهسازی و ۲) عمومیت. منظور از بهینهسازی این است که شبکه عصبی باید بتواند داده های train را به خوبی یاد بگیرد و پارامترهای مورد نیاز خودش را از آنها استخراج کند. با کمک معیارهای ارزیابی (مانند loss، accuracy و fscore) ما میتوانیم ببینیم که آیا شبکه عصبی توانسته دادههای یادگیری را یاد بگیرد یا خیر. نکته دیگر، عمومیت است. در عمومیت ما به دنبال این هستیم که شبکه عصبی بتواند نتایج خوبی بر روی دادههایی داشته باشد که تا به حال ندیده است (دادههای آزمون).
ممکن است که شبکه عصبی نتواند یادگیری خوبی داشته باشد. یعنی نتایج ارزیابی بر روی دادههای یادگیری (train) پایین باشد. در این حالت، نتایج بر روی داده های آزمون هم پایین است. به این حالت underfit شدن میگوییم.
از طرف دیگر، ممکن است که شبکه یادگیری خوبی بر روی داده های یادگیری داشته باشد، اما عمومیت نداشته باشد. به این معنا که نتایج ارزیابی بر روی دادههای یادگیری خیلی خوب است اما همین نتایج بر روی دادههای آزمون خوب نیست. در این میگوییم شبکه overfit شده است.
2. راه تشخیص overfit
برای تشخیص overfit کافی است که نمودار loss یادگیری (train loss) و loss ارزیابی (validation loss) را بر اساس epoch رسم کنیم. به طور کلی انتظار داریم که نمودار loss یادگیری، نزولی باشد. اگر نمودار loss ارزیابی هم نزولی باشد، یعنی underfit رخ داده است. در مقاله موجهه با underfit در شبکههای عصبی در این رابطه صحبت کردیم. اگر مشکل underfit را حل کنیم، به مشکل جدیدمان (overfit) برمیخوریم. در حالت overfit، نمودار validation loss پس از رسیدن به یک نقطه کمینه، به صورت صعودی ادامه مییابد. نمونه نموداری که در آن overfit رخ داده است در شکل زیر نشان داده شده است. همانطور که میبینیم، نمودار train loss به صورت نزولی است ولی نمودار validation loss پس از رسیدن به یک مقدار کمینه در epoch نشان داده شده، به صورت صعودی راه خود را ادامه میدهد.
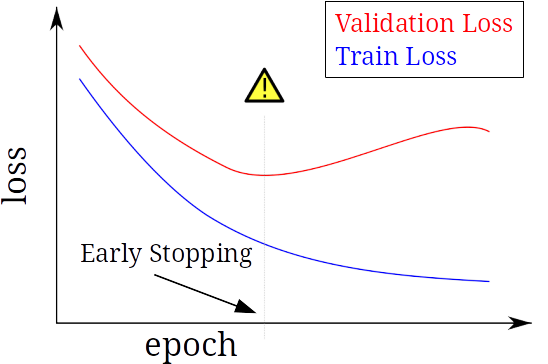
توجه داشته باشید که هدف ما از یادگیری این است که وزنهای شبکه عصبی را به گونهای تنظیم کنیم که میزان loss کاهش پیدا کند. با اینکار میزان معیار مطلوب ما (مثلا accuracy و یا fscore) افزایش پیدا میکند. از ظرف دیگر، برای بررسی دقیق مدل شبکه عصبی، باید آن را بر روی دادههای آزمون بررسی کنیم. معمولا نتیجه شبکه بر روی داده های آزمون، در حد نتیجه دادههای validation است.
3. اثر برطرف کردن overfit بودن شبکه چه چیزی باید باشد؟
در ادامه روشهایی برای برطرف کردن شبکه ارائه میشود. سوال این است که چگونه بفهمیم روش ارائه شده موثر بوده است؟ و یا اینکه اثر برطرف کردن overfit بودن شبکه چیست؟ پاسخ صحیح این است که شما باید نتیجه یک روش را بر روی دادههای آزمون (test) بررسی کنید. اما در برخی موارد میتوانیم از نمودار validation loss هم استفاده کنیم. در صورتی یک روش برطرف کردن overfit موثر است که کمترین مقدار loss در این نمودار، کاهش پیدا کرده باشد.
4. برطرف کردن overfit بودن شبکه
به طور کلی overfit بودن، به سه علت رخ میدهد: ۱) کم بودن دادهها، ۲) یادگیری با تعداد epoch زیاد و ۳) بزرگ بودن مدل. با توجه به این سه علت، برای برطرف کردن overfit باید این سه علت را برطرف کنیم.
4.1. برطرف کردن کم بودن تعداد دادهها
برای برطرف کردن کم بودن تعداد دادهها، باید تعداد داده ها را افزایش بدهیم. در اکثر موارد این کار امکان پذیر نیست. اما در برخی موارد، امکان ساخت داده جدید بر اساس دادههای موجود وجود دارد. مثلا معمولا ورودی شبکههای عصبی کانولوشن، تصویر است. یک از راه های ساخت تصویر جدید، اعمال تغییرات جزئی در تصاویر قبلی است. جابه جایی و چرخاندن تصویر نمونهای از این تغییرات است.
4.2. برطرف کردن تعداد epoch زیاد
برای برطرف کردن یادگیری با epoch زیاد، کافی است که تعداد epoch ها را کاهش بدهیم. اما توجه داریم که با کاهش epochها ممکن است دچار underfit بشویم. میزان epoch مورد نیاز که دچار underfit و overfit نشویم، از روی نمودار validation loss به دست میآید. در این نمودار، میزان epoch بهینه جایی است که کمترین مقدار loss را برای validation loss داریم. به این روش توقف زودهنگام (Early Stopping) گفته میشود.
4.3. برطرف کردن بزرگ بودن مدل
بزرگ بودن مدل به معنای زیاد بودن پارامترهای یادگیری است. برای اینکار شما باید پارامترهای یادگیری شبکه را محدود کنید و یا کاهش بدهید. پارامترهای یادگیری در شبکههای عصبی، تعداد و نوع لایهها و تعداد نرون در هر لایه است. علاوه بر آن در هر لایه، یک سری وزن یاد گرفته میشود. برای برطرف کردن بزرگ بودن مدل، سه روش وجود دارد: ۱) کوچک کردن مدل با کاهش لایهها و تعداد نرون لایهها، ۲) محدود کردن وزنهای لایهها (weight regularization)، و ۳) حذف برخی از خروجیهای لایهها با کمک dropout.
4.3.1. کوچک کردن مدل با کاهش لایهها و تعداد نرون لایهها
در این روش، شما باید تعداد لایهها و یا تعداد نرونهای لایهها را کم کنید. اینکار را به صورت تدریجی انجام بدهید و با هر تغییری که میدهید، اثر روش را بررسی کنید. اینکار را تا جایی انجام بدهید که روش موثر است. البته دقت کنید که کوچک کردن مدل منجر به underfit نشود.
4.3.2. محدود کردن وزنهای لایهها (weight regularization)
در روش محدود کردن وزن لایهها، یک مقدار جدید به تابع loss افزوده می شود که در نهایت منجر به محدود شدن مقدار وزنهای شبکه میشود. توجه داشته باشید که در نتیجه اینکار، مقدار loss در نمودار validation loss افزایش مییابد. اما در نهایت، مقدار loss بر روی دادههای آزمون کاهش مییابد. برای ارزیابی این روش، باید اثر آن را بر روی دادههای آزمون ببینید.
محدود کردن وزنها به سه روش انجام میشود: ۱) روش L1 regularization و ۲) روش L2 regularization و ۳) روش ترکیبی L1 و L2. روش L2 regularization با نام weight decay نیز معروف است.
نحوه استفاده از هر کدام از این روشها در لایههای یک شبکه در قطعه کد زیر نشان داده شده است:
from keras import regularizers
model.add(layers.Dense(16, kernel_regularizer=regularizers.l1(0.001), activation='relu'))
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
model.add(layers.Dense(16, kernel_regularizer=regularizers.l1_l2(l1=0.001, l2=0.001), activation='relu'))4.3.3. حذف برخی از خروجیهای لایهها با کمک dropout
در این روش، برخی از خروجیهای یک لایه صفر میشود که در نتیجه، تعداد وزنهای یادگیری شبکه کاهش مییابد. برای استفاده از این روش، باید لایه Dropout را بعد از لایههای معمولی (مثلا لایه Dense) استفاده کنیم. ورودی این لایه، نسبت تعداد خروجیهایی است که باید صفر بشوند. دقت کنید که لایه Dense را بعد از آخرین لایه شبکه نباید استفاده کرد.
برای ارزیابی این روش میتوانیم از نمودار validation loss استفاده کنیم.
نحوه استفاده از این روش، در کد زیر نشان داده شده است:
from keras.layers import Dropout
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dropout(0.5))5. جمعبندی
وجود overfit یکی از مشکلات اصلی شبکههای عصبی است. در این مقاله روش تشخیص و روشهای مواجهه با overfit را توضیح دادیم. تشخیص overfit با بررسی نمودار varidation loss انجام میشود. برای رفع overfit، سه روش معروف وجود دارد که در این مقاله به نحوه پیادهسازی آنها پرداختیم.