یادداشتها
علیرضا تجری
ایجاد:
جمعه، 07 آبان 1400
ویرایش
جمعه، 07 آبان 1400
ساخت یک شبکه عصبی پرسپترون چند لایه برای دستهبندی دوتایی در پایتون
پرسپترون چند لایه، سادهترین شبکه عصبی عمیق است. در این شبکه عصبی، لایههای Dense به صورت متوالی در پشت سر هم قرار میگیرند، در این مقاله نحوه ساخت و استفاده از یک شبکه عصبی برای دسته بندی دوتایی (Binary Classification) توضیح داده میشود.
روشهای توضیح داده شده در این مقاله بر روی یک مجموعه داده نمونه اعمال شدهاند. فایل کد و همه فایلهای استفاده شده از طریق لینک زیر قابل دریافت است.
1. گام اول: خواندن دادهها
قبل از طراحی شبکه، باید دادههایی را که میخواهیم پردازش کنیم، بخوانیم. برای خواندن داده ها از کتابخانه Pandas استفاده میکنیم. در این مقاله دادهها به صورت آماده وجود دارند. در صورتی که با نحوه آماده سازی داده ها آشنایی ندارید، میتوانید مقاله پیشپردازش دادهها با پایتون را مطالعه کنید.
import pandas as pd
basePath = "/content/drive/MyDrive/blog/mlp-binary-classification/"
train_feats = pd.read_csv(basePath+"train_feats.csv")
test_feats = pd.read_csv(basePath+"test_feats.csv")
train_target = pd.read_csv(basePath+"train_target.csv")
test_target = pd.read_csv(basePath+"test_target.csv")برای مشاهده و بررسی دادهها میتوانیم از describe استفاده کنیم. دقت کنید که همه مقادیر مربوط به دادههای یادگیری بین 0 و 1 هستند. اما در مورد داده های آزمون، ممکن است اینطور نباشد. مثلا کمترین مقدار یک ستون از 0 کمتر باشد و بیشترین مقدار یک ستون از 1 بیشتر باشد. در مورد دادههای ما، این اتقاق افتاده است.
train_feats.describe(include='all')| intercolumnar distance | upper margin | lower margin | exploitation | row number | modular ratio | interlinear spacing | weight | peak number | modular ratio/ interlinear spacing | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 8344.000000 | 8344.000000 | 8344.000000 | 8344.000000 | 8344.000000 | 8344.000000 | 8344.000000 | 8344.000000 | 8344.000000 | 8344.000000 |
| mean | 0.228808 | 0.006362 | 0.060381 | 0.576617 | 0.822838 | 0.123502 | 0.125857 | 0.240800 | 0.110971 | 0.589626 |
| std | 0.066259 | 0.011215 | 0.021374 | 0.106865 | 0.164919 | 0.019067 | 0.014573 | 0.058065 | 0.022422 | 0.088562 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.219984 | 0.005579 | 0.061623 | 0.521054 | 0.850746 | 0.113343 | 0.125258 | 0.208556 | 0.103337 | 0.543997 |
| 50% | 0.231265 | 0.006104 | 0.064430 | 0.586549 | 0.865672 | 0.122273 | 0.128041 | 0.246615 | 0.112159 | 0.586422 |
| 75% | 0.241741 | 0.006771 | 0.066970 | 0.646610 | 0.865672 | 0.132577 | 0.130427 | 0.278269 | 0.120980 | 0.636167 |
| max | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
test_feats.describe(include='all')| intercolumnar distance | upper margin | lower margin | exploitation | row number | modular ratio | interlinear spacing | weight | peak number | modular ratio/ interlinear spacing | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 2086.000000 | 2086.000000 | 2086.000000 | 2086.000000 | 2086.000000 | 2086.000000 | 2086.000000 | 2086.000000 | 2086.000000 | 2086.000000 |
| mean | 0.227047 | 0.006223 | 0.060109 | 0.577577 | 0.823801 | 0.123378 | 0.125475 | 0.240850 | 0.111739 | 0.591369 |
| std | 0.058152 | 0.002522 | 0.019715 | 0.107459 | 0.168651 | 0.016779 | 0.010388 | 0.057144 | 0.020103 | 0.087831 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.059076 | 0.000000 | -0.004785 | 0.020163 | 0.000000 |
| 25% | 0.219984 | 0.005559 | 0.061490 | 0.521054 | 0.850746 | 0.113343 | 0.125158 | 0.209811 | 0.103967 | 0.547212 |
| 50% | 0.231265 | 0.006084 | 0.064364 | 0.588473 | 0.865672 | 0.122273 | 0.128041 | 0.246857 | 0.112789 | 0.588782 |
| 75% | 0.242546 | 0.006771 | 0.066970 | 0.649325 | 0.865672 | 0.132577 | 0.130427 | 0.276956 | 0.121610 | 0.637185 |
| max | 1.000000 | 0.056373 | 0.200509 | 1.000000 | 1.000000 | 0.204017 | 0.179735 | 0.470199 | 0.170758 | 0.939281 |
مقدار هدف (target) برای همه ویژگیها در دادههای یادگیری و آزمون، یا 0 است و یا 1.
train_target.value_counts()Class
0 4876
1 3468
dtype: int64test_target.value_counts()Class
0 1268
1 818
dtype: int642. گام دوم: طراحی لایههای شبکه عصبی
ابتدا پکیجهای مورد نیاز را import میکنیم.
from keras.models import Sequential
from keras.layers import Denseبرای ایجاد شبکههای عصبی پرسپترون چند لایه، از مدل Sequential استفاده میکنیم.
در این مدل، لایههای شبکه عصبی به صورت پشت سرهم قرار میگیرند. برای این مدل، ۶ لایه در نظر گرفتیم. همه این لایهها از نوع Dense هستند. در لایههای Dense، همه ورودیهای لایه به همه نرونها متصل میشوند. اولین پارامتر Dense، تعداد خروجی لایه Dense است. برای اولین لایه Dense، باید تعداد ورودیهای لایه را هم مشخص کنیم. تعداد ورودیهای اولین لایه برابر است با تعداد ویژگیها. تعداد ویژگیها هم از طریق train_feats.shape[1] به دست میآید. البته به جای train_feats.shape[1] میتوانیم مقدار آن که در این مثال ما برابر با 10 است را بنویسیم. برای لایههای بعدی، تعیین تعداد خروجیهای لایه کافی است. تعداد ورودیهای لایههای بعد، برابر است با تعداد خروجیهای لایه قبل. برای شبکههای عصبی عمیق، معمولا تابع فعالسازی relu در نظر گرفته میشود. برای لایه آخر، با توجه به اینکه مسئله ما دسته بندی دوتایی است، تابع فعال سازی را sigmoid و تعداد خروجیها را 1 در نظر گرفتیم.
model = Sequential()
model.add(Dense(20, activation='relu', input_dim=train_feats.shape[1]))
model.add(Dense(80, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))3. گام سوم: تعیین نحوه آموزش شبکه عصبی و معیار ارزیابی
برای تعیین نحوه آموزش شبکه عصبی باید دو پارامتر اصلی را تعیین کنیم.
پارامتر اول، تابع loss است. این تابع مشخص میکند که مقدار یادگرفته شده تا چه اندازه با مقدار واقعی اخلاف دارد. هر چه مقدار این تابع کمتر باشد، یادگیری بهتر انجام شده است. برای مسئله ما (دستهبندی دو کلاسه) تابع binary_crossentropy، بهترین گزینه است. برای مسئل دیگر مانند دسته بندی چند کلاسه و یا رگرسیون، توابع loss
دیگری وجود دارد.
پارامتر دوم، تابع بهینهساز و یا optimizer است. این تابع تعیین میکند که با توجه به مقدار loss چگونه، ضرایب وزنهای شبکه را باید تغییر داد. در این مثال ما از adam استفاده کردیم. توابع بهینهسازی دیگری هم وجود دارد که میشد از آنها استفاده کرد.
معیاری که ما برای ارزیابی از آن استفاده میکنیم، دقت و یا accuracy است. در پارامتر metrics این معیار را مشخص کردیم. میتوانیم از معیارهای دیگر هم استفاده کنیم.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])3.1. مشاهده شبکه عصبی
یکی از امکانات خوب keras امکان دیدن مدلی است که طراحی کردیم. با کمک دستور زیر، میتوانیم مدل را ببینیم.
model.summary()Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_19 (Dense) (None, 20) 220
_________________________________________________________________
dense_20 (Dense) (None, 80) 1680
_________________________________________________________________
dense_21 (Dense) (None, 40) 3240
_________________________________________________________________
dense_22 (Dense) (None, 20) 820
_________________________________________________________________
dense_23 (Dense) (None, 10) 210
_________________________________________________________________
dense_24 (Dense) (None, 1) 11
=================================================================
Total params: 6,181
Trainable params: 6,181
Non-trainable params: 04. گام چهارم: آموزش شبکه
برای آموزش شبکه، از تابع fit بر روی مدل استفاده میکنیم. در این تابع، باید همه دادههای یادگیری را در قالب بردار ویژگیها و بردار هدف تعیین کنیم. در این مثال توجه داشته باشید که مقدار هدف در ستونی با نام Class در train_target قرار دارد. پارامتر epochs تعیین میکند که چند بار باید کل دادههای یادگیری را به شبکه بدهیم. پارامتر batch_size تعین میکند که دادهها را چند تا چند تا به شبکه بدهیم. در این مثال ما دادهها را ۵۱۲ نمونه (=سطر)، ۵۱۲ نمونه، به شبکه میدهیم. پارمتر validation_split برای جدا کردن بخشی از داده های یادگیری برای ارزیابی است. در هر مرحله یادگیری بر روی داده های ارزیابی انجام نمیشود. از این داده ها برای ارزیابی داخلی استفاده میکنیم. ارزیابی اصلی با داده های آزمون است. خروجی تابع fit یک شی است که دادههای مفیدی از فرآیند آموزش دارد. در گام بعد ما این دادهها را نشان میدهیم. با ارزیابی این دادهها، میتوانیم وضعیت یادگیری شبکه را بسنجیم. بیشترین زمان اجرا، مربوط به این تابع است.
history = model.fit(
train_feats, train_target['Class'], batch_size=512,
epochs=4000, validation_split=0.2)بخشی از خروجی این تابع به صورت زیر است:
Epoch 3995/4000
14/14 [==============================] - 0s 10ms/step - loss: 0.1903 - accuracy: 0.9128 - val_loss: 0.5907 - val_accuracy: 0.8556
Epoch 3996/4000
14/14 [==============================] - 0s 9ms/step - loss: 0.1908 - accuracy: 0.9091 - val_loss: 0.5949 - val_accuracy: 0.8616
Epoch 3997/4000
14/14 [==============================] - 0s 8ms/step - loss: 0.1856 - accuracy: 0.9139 - val_loss: 0.5940 - val_accuracy: 0.8646
Epoch 3998/4000
14/14 [==============================] - 0s 10ms/step - loss: 0.1883 - accuracy: 0.9110 - val_loss: 0.6269 - val_accuracy: 0.8448
Epoch 3999/4000
14/14 [==============================] - 0s 11ms/step - loss: 0.2196 - accuracy: 0.8953 - val_loss: 0.5928 - val_accuracy: 0.8652
Epoch 4000/4000
14/14 [==============================] - 0s 9ms/step - loss: 0.2018 - accuracy: 0.9041 - val_loss: 0.5811 - val_accuracy: 0.85925. گام پنجم: ارزیابی شبکه در حین آموزش
خروجی تابع fit در کد قبل، متغیر history است. در این متغیر، اطلاعات مربوط به فرآیند یادگیری وجود دارد. یکی از مهمترین این اطلاعات، مقدار loss و val_loss به ازای هر epoch است. loss نشان دهنده میزان loss بر روی داده های یادگیری و val_loss نشاندهنده میزان loss بر روی دادههای ارزیابی (validation) است.
با استفاده از کتابخانه matplotlib میتوانیم نمودار این مقادیر را رسم کنیم.
import matplotlib.pyplot as pltدر کد پایین، رسم نمودار توسط دو خط بالا انجام میشود؛ نمایش نمودار نیز در خط آخر انجام میشود. چهار خط میانی، عناوین ستون ها و نمودار را مشخص میکنند.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()نمودار خروجی به صورت زیر است:
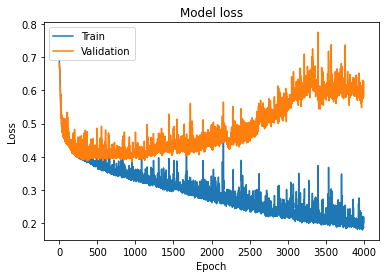
همچنین، از آنجا که ما معیار دقت (accuracy) را هم به عنوان یکی از معیارهای ارزیابی در تابع compile معرفی کردیم، میتوانیم میزان دقت در حین یادگیری را بر روی داده های یادگیری و ارزیابی مشاهده کنیم. کد زیر اینکار را انجام میدهد.
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()نمودار خروجی به صورت زیر است. همانطور که مشخص است، مقدار دقت برای داده های یادگیری نزدیک به 90% و برای دادههای ارزیابی حدود 86% است.
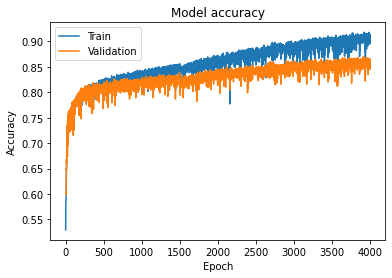
6. گام ششم: ارزیابی شبکه بر روی داده های آزمون
برای ارزیابی شبکه بر روی دادههای آزمون از تابع evaluate بر روی مدل استفاده میکنیم. در اینجا ما به دقت 86% بر روی دادههای آزمون رسیدیم.
test_loss, test_accuracy = model.evaluate(test_feats, test_target['Class'])66/66 [==============================] - 0s 1ms/step - loss: 0.3953 - accuracy: 0.86347. جمعبندی
در این مقاله، ما نحوه ساخت یک شبکه عصبی برای دسته بندی دو کلاسه با استفاده از کتابخانه keras در پایتون را توضیح دادیم. همانطور که دیدیم، اینکار خیلی راحت است. نکته مهمی که در این مقاله به آن نپرداختیم، نحوه بهبود مدل است. انشالله در مقالههای بعدی به این موارد خواهیم پرداخت. شما برای بررسی دقیقتر اینمقاله، میتوانید همه کدها و فایلهای استفاده شده را از طریق لینک زیر دریافت کنید: